
AWS Glue – Simple, flexible, and cost-effective ETL

Organizations gather huge volumes of data which, they believe, will help improve their products and services. For example, a company may collect data on how its customers use its products, customer data to know its customer base, and website visits. However, a large portion of the collected data is never even brought to use. According to IDC, 90% of the unstructured data is never analysed. Such data is known as dark data.
Dark data, if not handled properly can pose serious challenges to the organization. Therefore, it is very important for any organization to have an effective means in place to transform the large volume of unstructured data gathered from multiple sources to a format that can provide them business insights and be of value to them.
This is where ETL process comes to the rescue and helps them consolidate data from multiple sources to be transformed and loaded to a single datastore.
AWS provides a fully managed ETL service named Glue. You can use AWS Glue to build a data warehouse to organize, cleanse, validate, and format data.
This post walks you through a basic process of extracting data from different source files to S3 bucket, perform join and renationalize transforms to the extracted data and load it to Amazon Redshift for warehousing.
This example uses a dataset that was downloaded from http://everypolitician.org/ to the sample-dataset bucket in Amazon S3: s3://awsglue-datasets/examples/us-legislators/all. The dataset contains data in JSON format about United States legislators and the seats that they have held in the US House of Representatives and Senate.
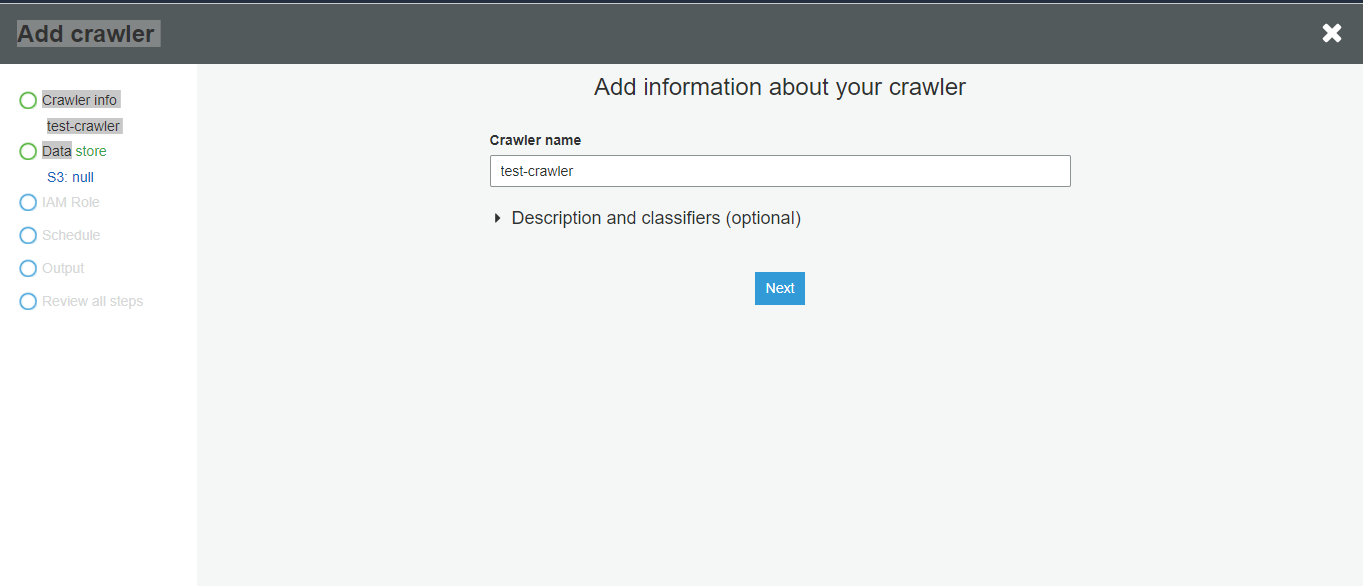
- You start by creating a database in the Glue console which will catalog metadata of the source.

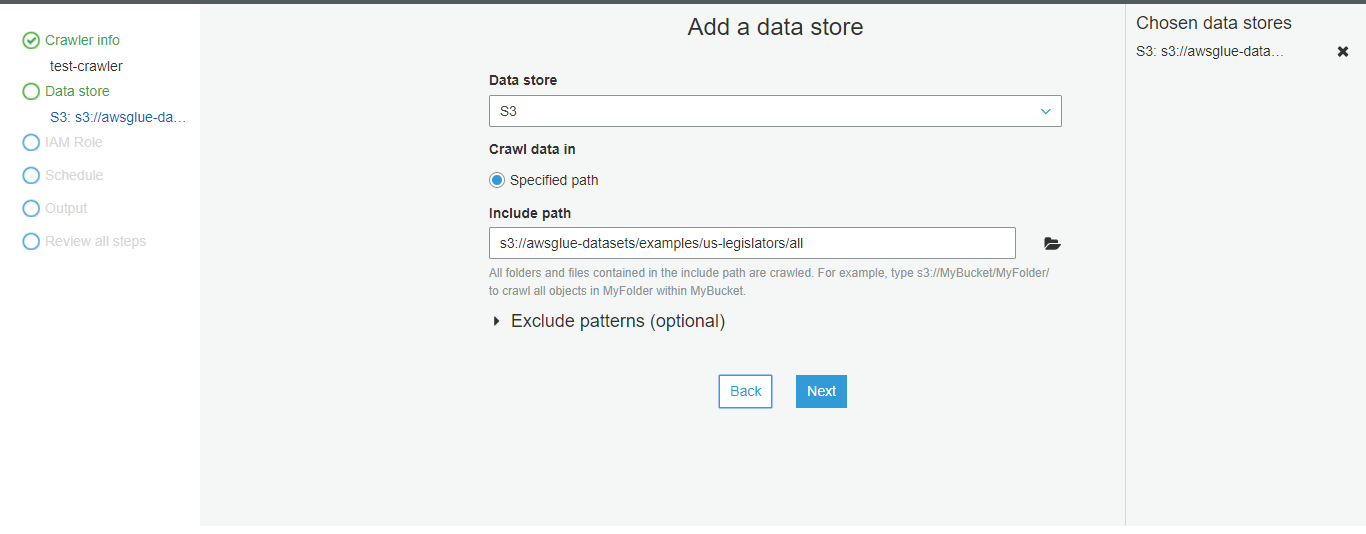
- Create a new crawler that can crawl the s3://awsglue-datasets/examples/us-legislators/all dataset into the database named legislators that you just created.

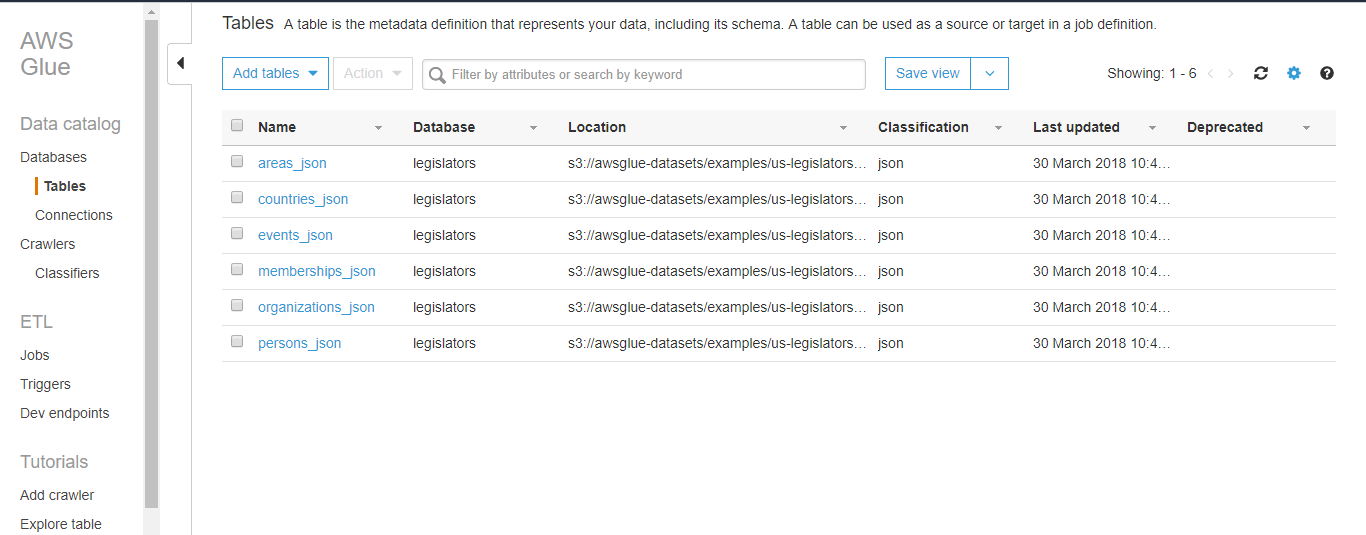
The crawler creates the following metadata tables:
- Next, you need to create a target redshift cluster prior to running the job.
- Configure a connection endpoint of the redshift cluster previously created and specify the jdbc url of the cluster in the connection settings.
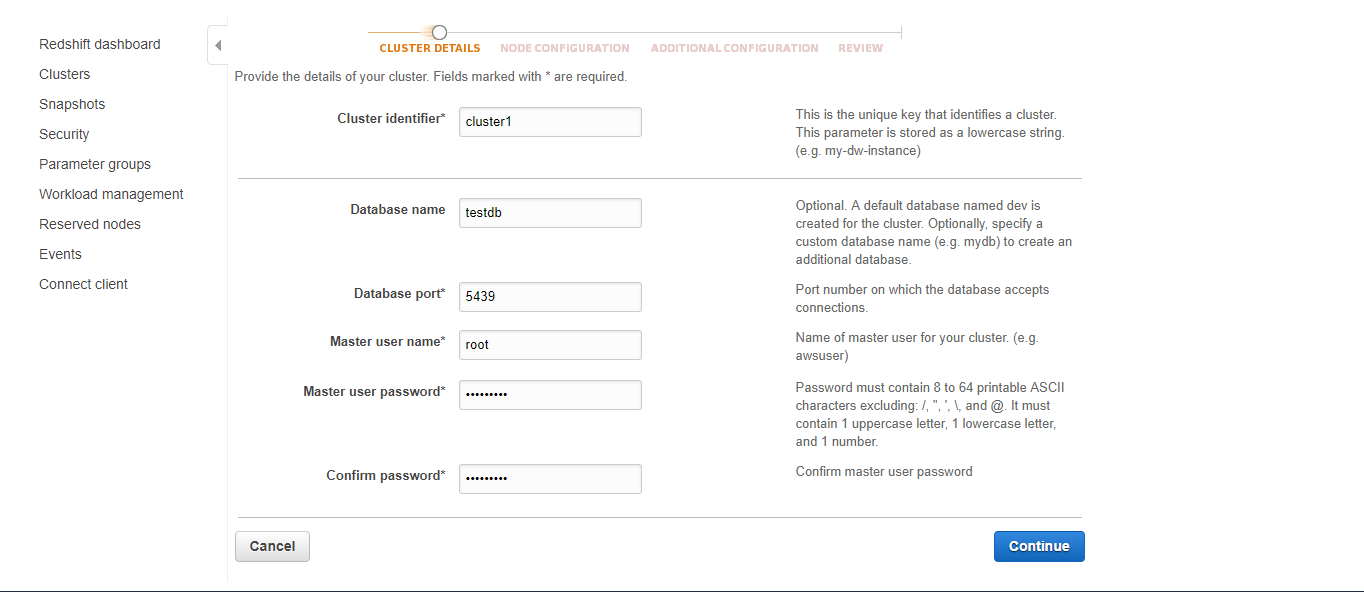
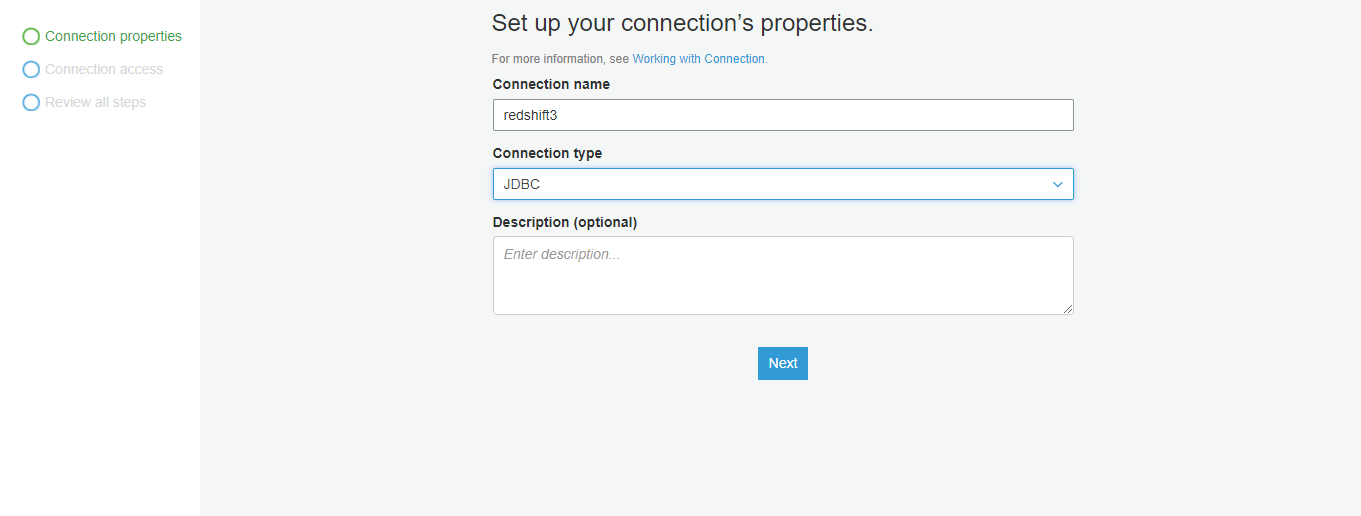
- Last step is to create a job in the glue console, specify the source and target connection endpoints and script that performs the transform and load part.


You can get the sample code from the following GitHub url: Here
Paste the script, save it and then run the job.
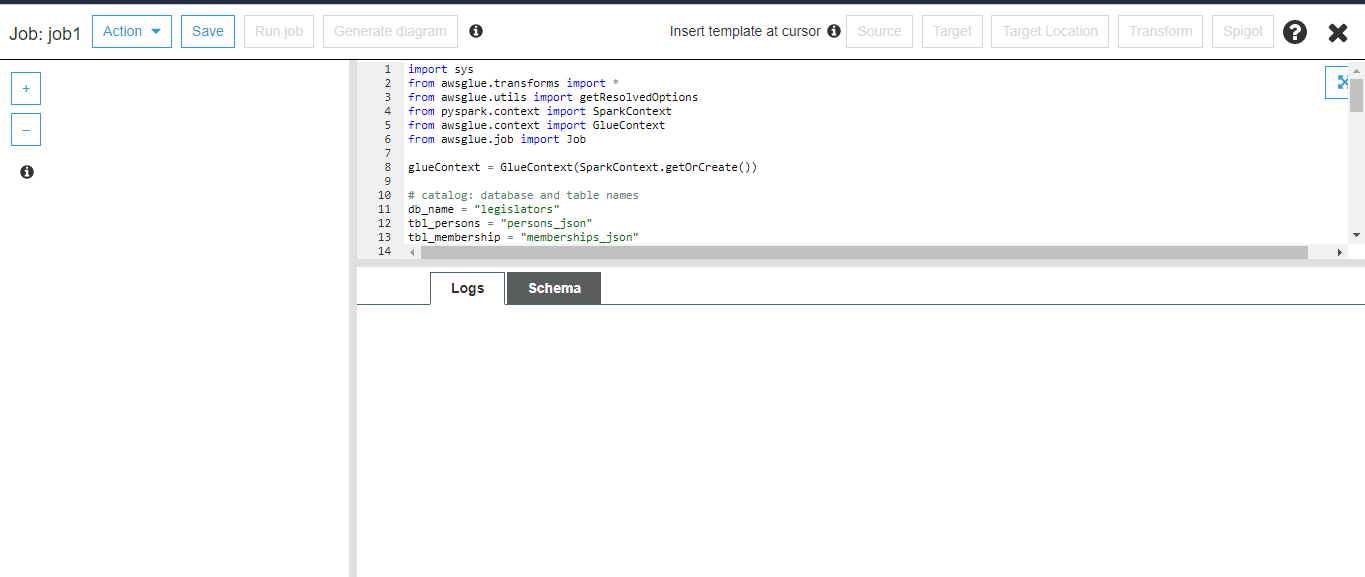
Your job would apply the transformations and load the transformed data to the redshift cluster for warehousing.
Overall, AWS Glue is very flexible. It lets you accomplish, in a few lines of code, what normally would take days to write.
You can read more about AWS Glue on the following link: https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html
Contributed by :
Nikita Punjabi
https://www.linkedin.com/in/nikita-p-221406162/